
What is the S3 Bucket?
AWS S3 bucket is a directory/folder where we can store any kind of data except application or OS. Why AWS called S3 bucket for directory/folder because bucket has " Sx3" Simple Storage Service. In S3 bucket we can store any amount of data and retrieve from anywhere on web. S3 bucket is extremely durable, highly available, and infinitely scalable data storage infrastructure. You can store unlimited objects and volume in S3 bucket but single object size must be range of 0 - 5 terabytes and you can upload at one time 5 gigabytes of large size of object. Amazon recommends that if you have object more than 100 megabytes use Multipart Upload.
S3 object storage,
We can store objects up to 5TB per buckets
Data is stored across a minimum of 3 AZ's
S3 bucket name always in a universal namespace (globally unique name)
S3 object version history gets stored/tracked
Consistency
- Read after write for PUTS of new objects
- Eventual consistency for overwrite PUT and DELETE (may take small time to get newer version of file)
Service Level Agreement (SLA)
- 99.9% availability guarantee
- 11x 9s durability guarantee
Storage Classes
Standard
- 99.99% availability
- 11x 9s durability
Intelligent tiering
- Uses ML to optimize costs based on how often objects are accessed
- S3 Lifecycle management for automatic migration of objects to other S3 Storage Classes
- 99.9% availability
- 11x 9s durability
Infrequently accessed (IA)
- Don't need much but access immediately when required
- Cheaper than Standard Storage but charge retrieval fee
- Minimum storage time is 30 days (you will be charged if you delete earlier)
- 99.9% availability
- 11x 9s durability
One zone - IA (similar to RRS which is being phased out)
- Only stored in one AZ, lower cost
- If you don't care about durability necessarily
- 99.5% availability
- 11x 9s durability
Glacier (separate service)
- Minutes to hours for retrieving objects
- expedited - typically 1-5 mins
- standard - 3-5 hours
- Cheap storage class
- For items moved to Glacier, they will show in the S3 console (not Glacier screen)
- Retrieving from Glacier
- You submit the request, then eventually a copy of the file(s) will be made available in the S3 IA class, you decide how long to keep copy there
- You can then do a normal S3 GET
- Minimum storage time is 90 days, also early deletion fee (after 90 days, its free)
- you can't upload directly to Glacier through the console, need to transition from S3 or use CLI/API
- 99.99% availability
- 11x 9s durability
Glacier Deep Archive
- 12 hours required to retrieve objects
- Very lowest cost option for objects storage
- Mostly for long term objects storage, 7-10 year storage requirements
- Minimum billable size is 40kB (smaller than 40kb you will be charged)
- Substitute of tape libraries
- 180 days is minimum storage time
- 99.99% availability
- 11x 9s durability
Security, Replication and Versioning can apply for your objects to protect and manage your data.
Note: Before you are going to connect S3 Bucket make sure you have done one of the following steps:
- If you have EC2 instance installed in a Public IP address then you have to route table entry with the default route pointing to an Internet Gateway.
- Private EC2 (VPC) instance with a default route through a NAT gateway.
- Private EC2 (VPC) instance with connectivity to Amazon S3 using a Gateway VPC Endpoint.
Creating S3 Buckets
- Select S3 from Storage consol

- Select Create bucket

- Give a name to your bucket but name should be globally unique name
- You can make bucket private by ticking in "Block all Public Access"
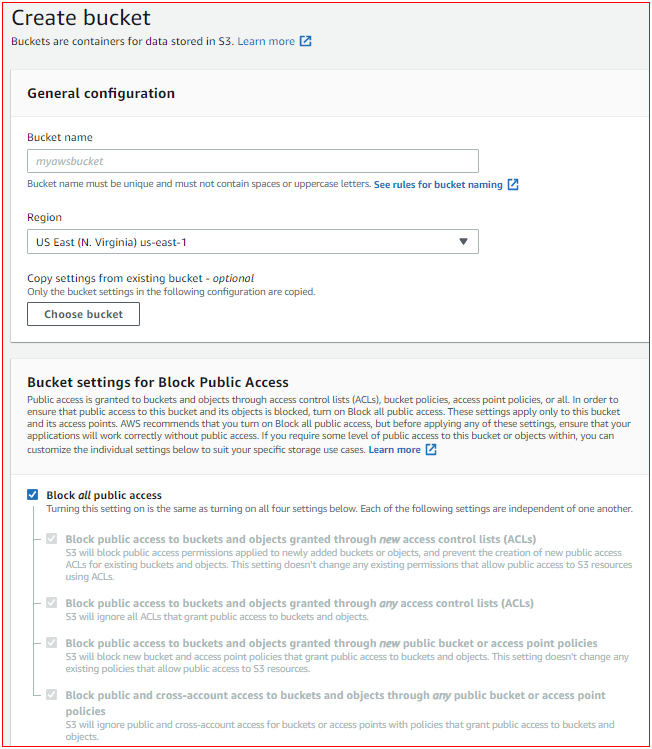
There are some options you can apply for buckets:
- Bucket versioning , where the bucket is configured to save older versions of objects.
- Tags , the purpose of Cost Allocation
- Default Encryption , if it is enable then objects will automatically encrypted
- Object Lock , if it is enable then write only once but can read many more
Let's start creating EC2 Instance, Role and attach the role into EC2 Instance
For this EC2 installation steps we are going to use default VPC, Subnet and Internet gateway but we are creating our own security group to access S3 bucket through SSH and validating port 80 for user-data installed through web browser.
Step 1 - Installing EC2 Instance
Under Compute select EC2
Under EC2 Dashboard select Launch Instance
Choose an Amazon Machine Image (AMI)
- Select Amazon Linux 2 AMI (HVM), SSD Volume Type - ami-09d95fab7fff3776c (64-bit x86) / ami-02b5d851009884e20 (64-bit Arm)

Choose Instance Type
- Select Family : General Purpose, Type : t2.micro / free tier eligible
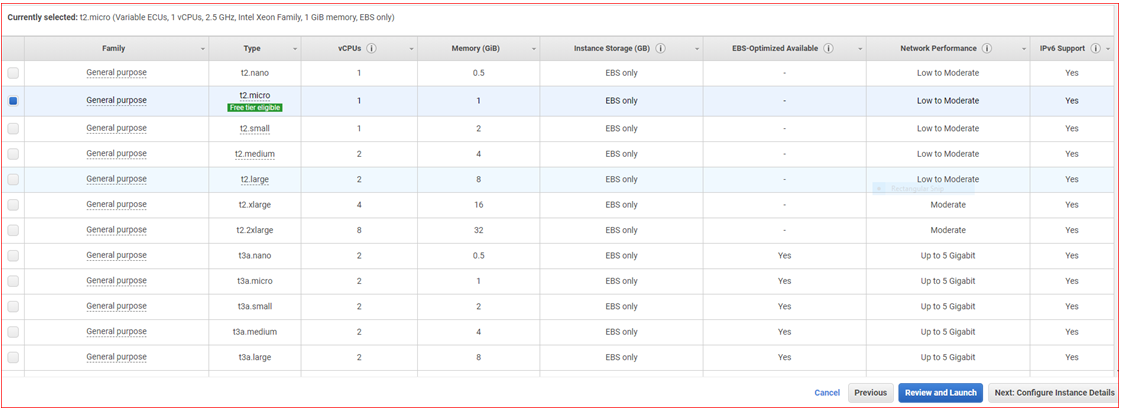
- Click on Next: Configure Instance Details
Configure Instance Details
- Select Network : Default VPC
- Select Subnet : Select any available Default Subnet
- Auto-assign Public IP: Use Subnet Setting( Enable )
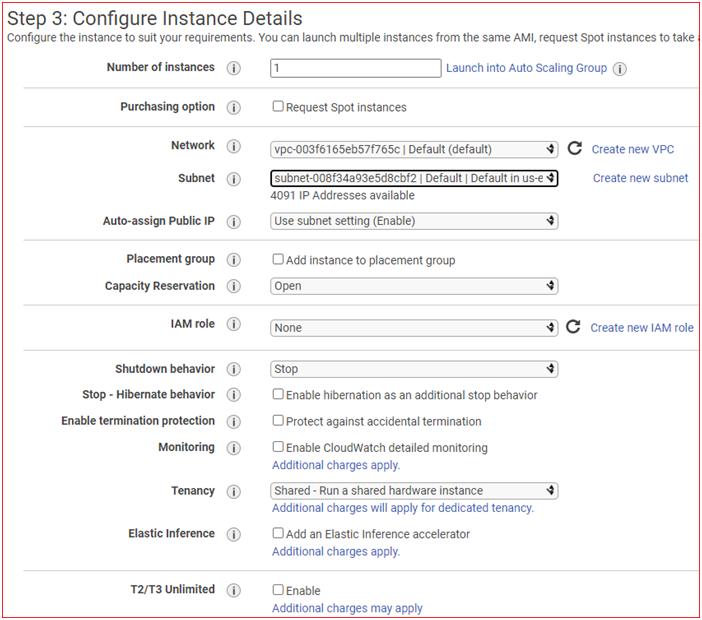
- Click on Advance details
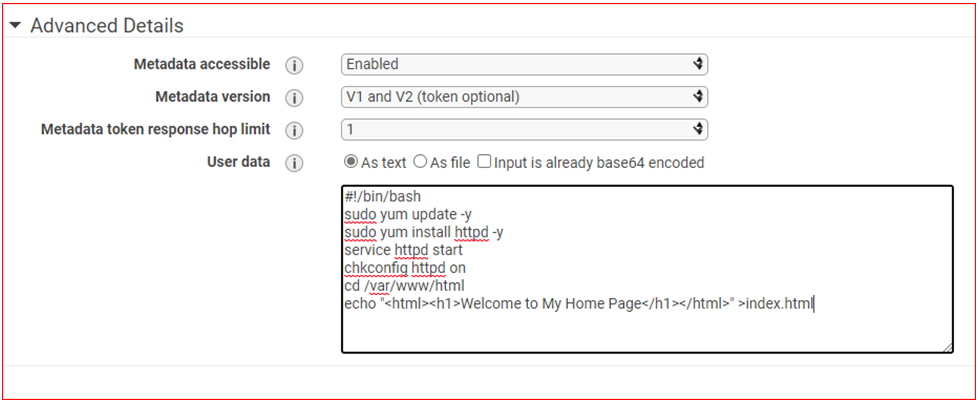
Type above mentioned user-data for updating instance, installing Apache server and creating a simple web page for testing purpose.
- Click on Add Storage
- Add Storage
- Do not Add Volume Click on Add Tags
- Add Tags
- Click on Add Tag Key : Name and Value : S3_Bucket
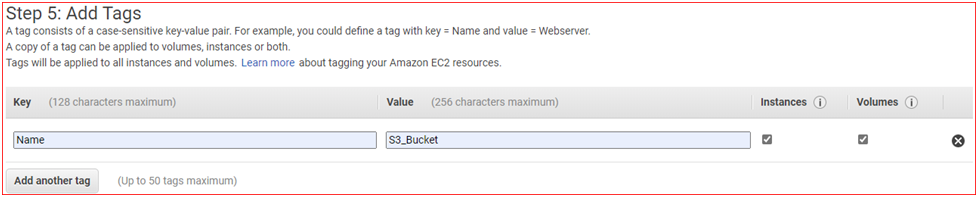
- Click on Next: Configure Security Group
Configure Security Group
- Assign Security Group Select: Create a new security group
- Security Group Name: S3_Bucket
- Description: S3_Bucket
- Add firewall** rules** as per below:
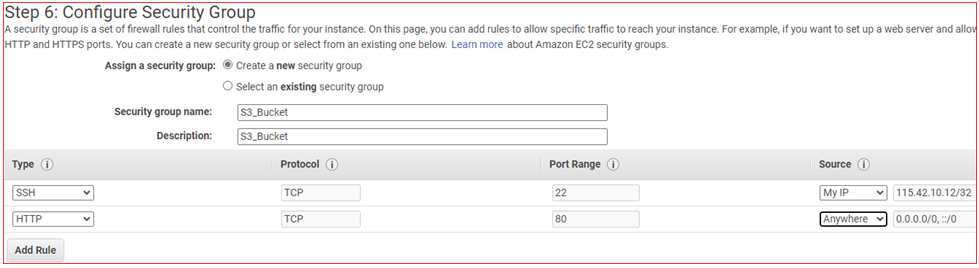
- Click on Review and Launch
Review Instance Launch
- Review and Make sure everything perfect, Click on Launch
Select an existing key pair or create a new key pair
- Select: Create new key pair
- Key pair Name: S3_Bucket
- Select: Download Key Pair (Do not lose it!! we will need it later for SSH connection to EC2)
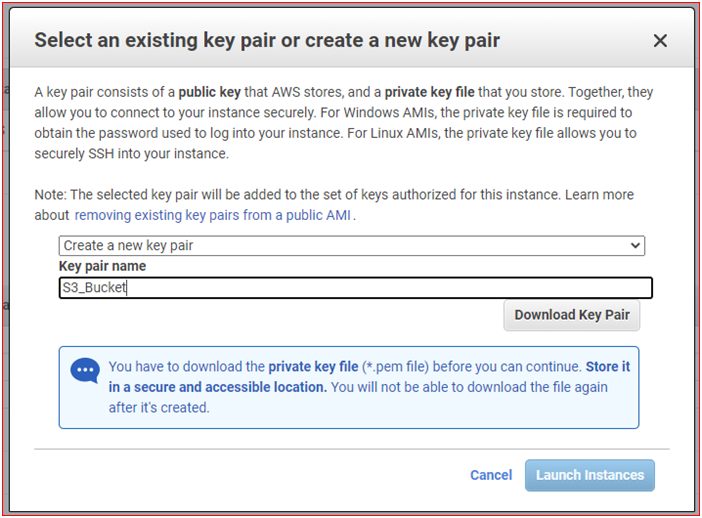
Click on Launch Instances
Step one is completed!!
Note: You can verify whether your user-data is installed or not by using your IPv4 Public IP or Public DNS (IPv4) name in Web Browser:
- Go to EC2 and select Running instances
- Select your Instance and copy Public DNS or Public IP
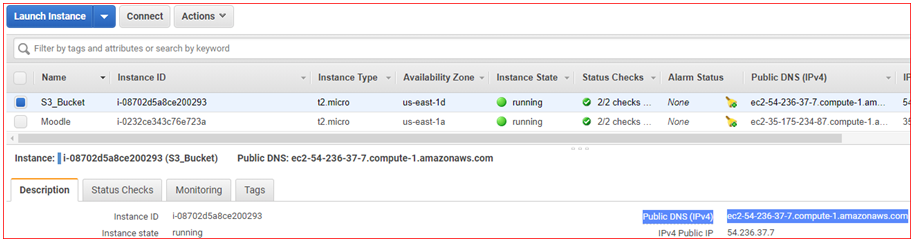
- Paste Public DNS or Public IP in Web Browser
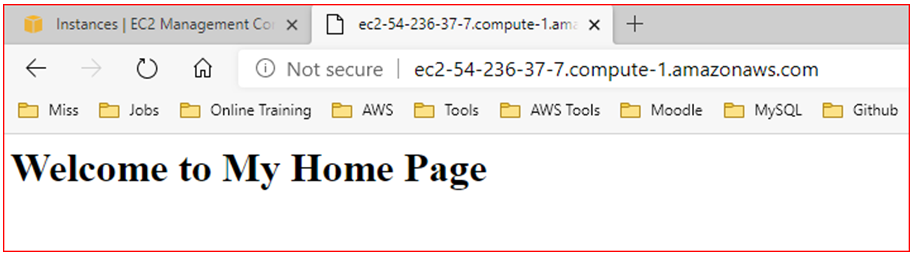
If you can see above web page then user-data is installed in EC2 instance.
You have created an instance with user-data included but without instance's role attach on it. Still you can't access S3 bucket from EC2 Instances therefore we have to create a role to grant access to S3 bucket. Follow below steps to complete creating and attaching EC2 role.
Step 2 - Create an IAM instance role to grant access to S3 bucket
- Open IAM consol
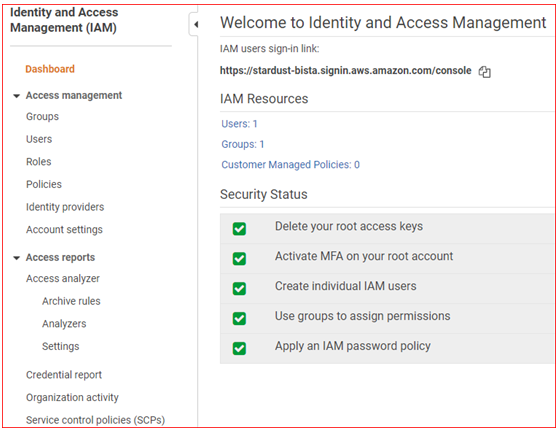
- Select Roles , and then Click on Create role
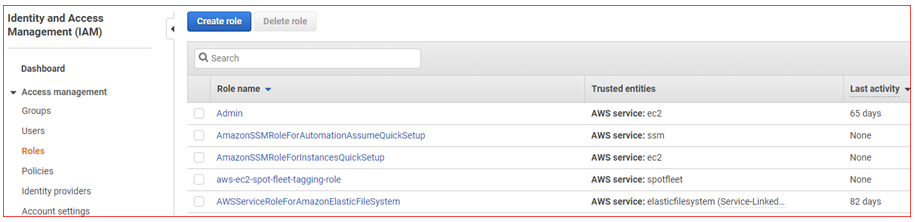
- Click on AWS Service , and then choose EC2
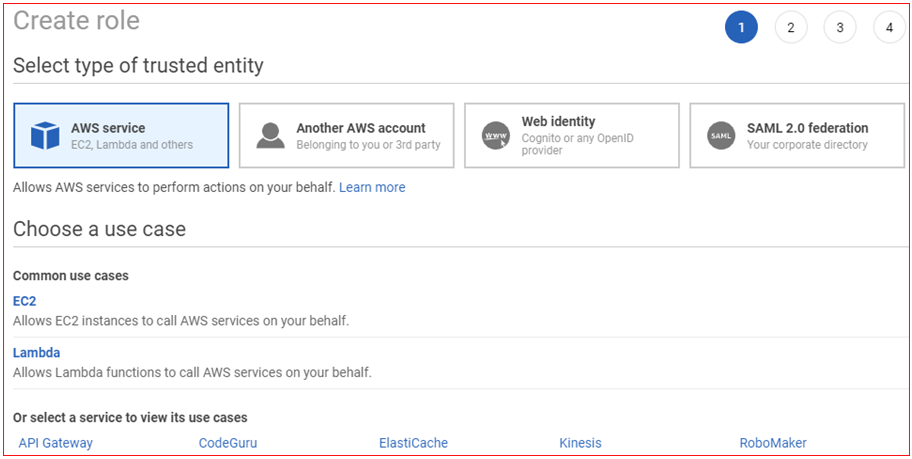
- Click on Next: Permissions
- Filter for the AmazonS3FullAccess managed policy and then select it
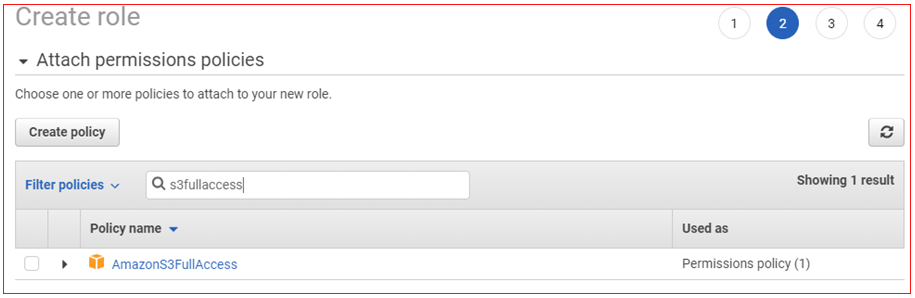
- Click on Next: Tags , and then select Next: Review
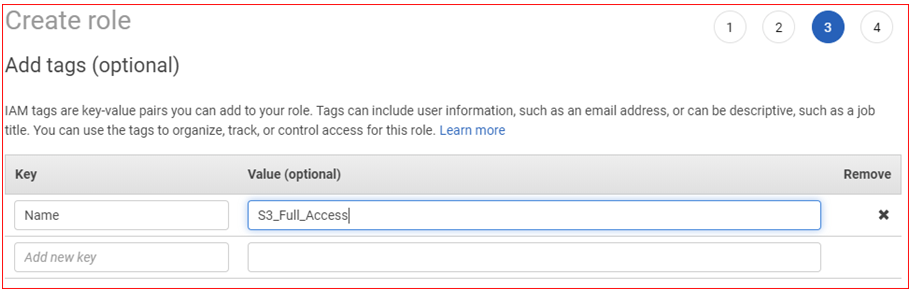
- Type a Role name , and then click on Create role
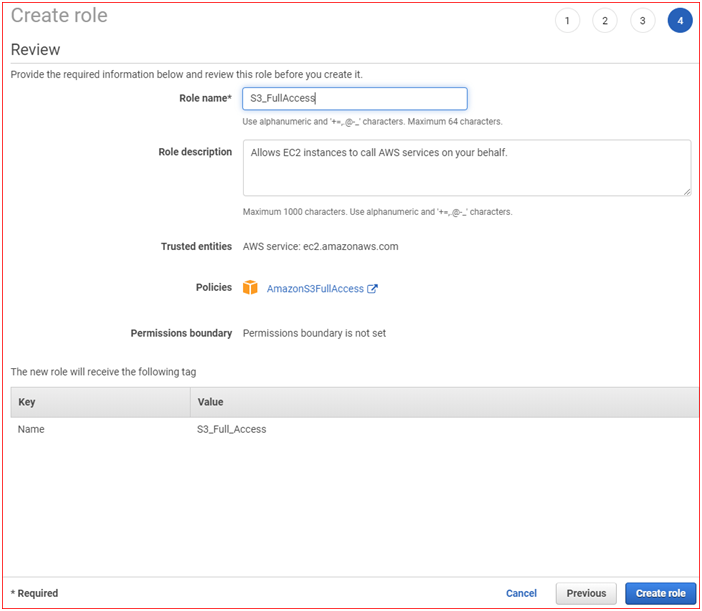
At this stage you have created a role which allows us for full access to S3 bucket. Now we have to attach this role to EC2 instance to grant access to S3 bucket.
Step 3 - Attaching Role to EC2 Instance
- From console under compute open Amazon EC2 dashboard and
select running instances
- Select the instance that you want to grant full access to S3 bucket (e.g. S3_Bucket)
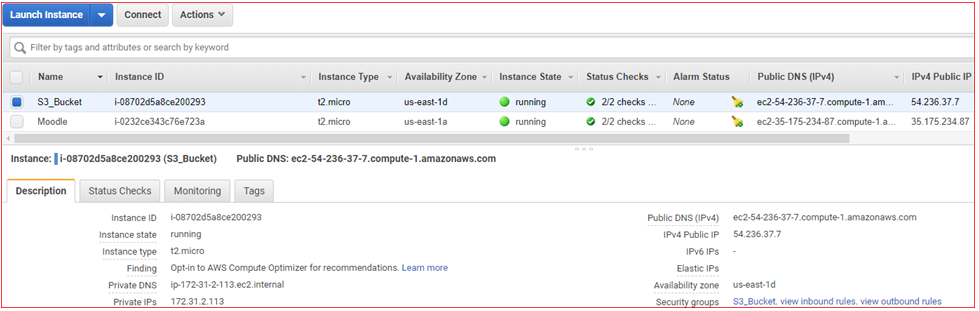
- Select the Actions tab from top left menu, select Instance Settings , and then choose Attach/Replace IAM role
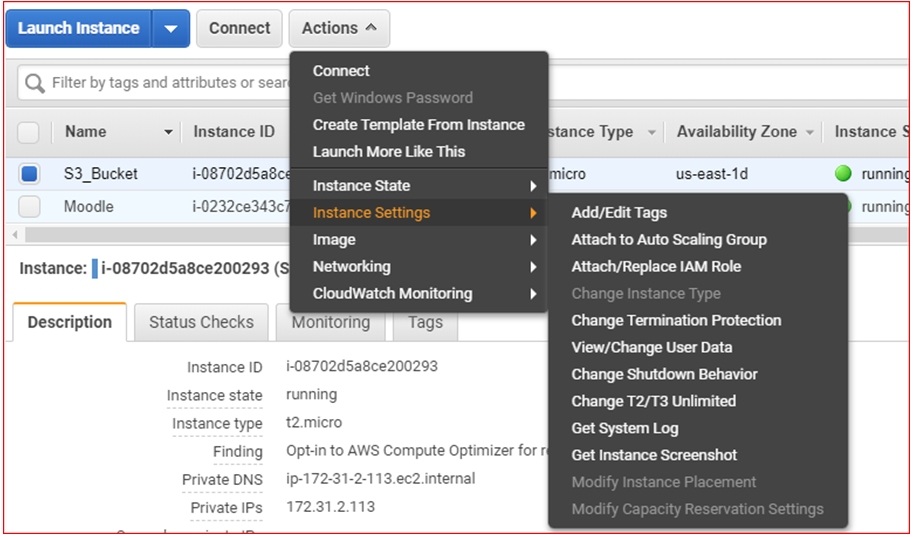
- Choose the IAM role that you just created, click on Apply , and then choose Close
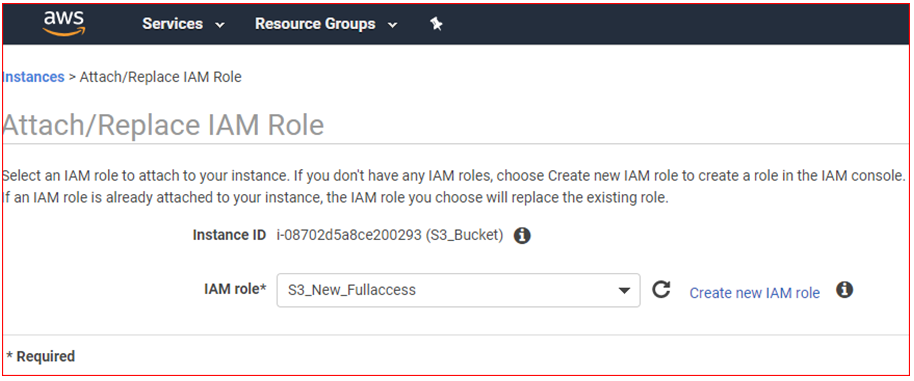
So far, you have created a role and attached to EC2 instance for full access to S3 bucket.
Validate access to S3 buckets
- Install the AWS CLI or use Linux, Mac Terminal
- Change directory or folder where your downloaded Key Pair file is located (e.g S3_Bucket for this guide).
- If you are using AWS CLI type command below:
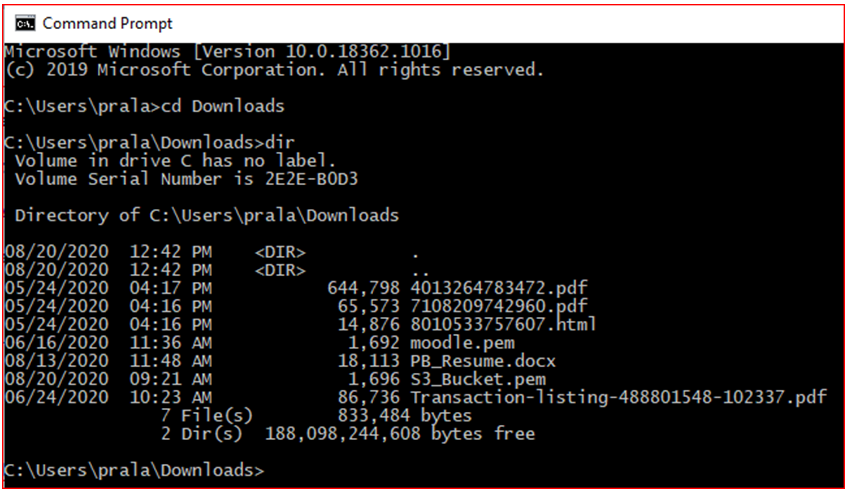
- ssh ec2-user@Public IP (IPv4) -i key pair
- Example: ssh ec2-user@54.236.37.7 -i S3_Bucket
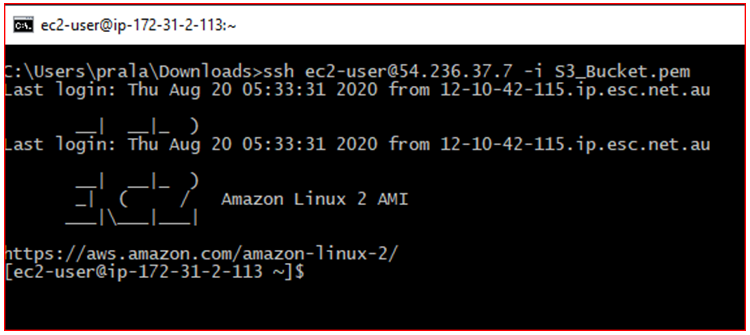
Once you have connected to EC2 instance type below AWS command to access S3 Bucket:
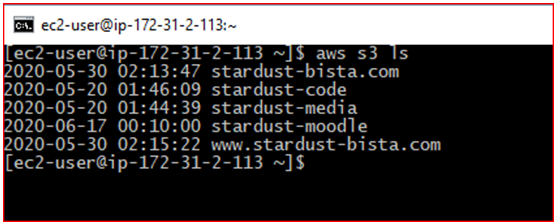
- aws s3 ls (List all of the buckets)
- curl http://169.254.169.254/latest/user-data (Displays your user-data)
Well done!!
You have connected to EC2 instance and accessed to S3 Bucket using AWS CLI.
But if you are using Linux Terminal then follow below mentioned steps:
- Go to Applications Menu \> System Tools \> Terminal
- Change Directory/Folder where you have saved your Key Pair file
- Gives the user read permission, and removes all other permission
- chmod 400 S3_Bucket
- Now type this command to connect EC2 Instance
- ssh ec2-user@Public IP (IPv4) -i key pair
- Example: ssh ec2-user@54.236.37.7 -i S3_Bucket
Once you have connected to EC2 instance type below AWS command to list all S3 Buckets:
- aws s3 ls
Now you can perform other task in S3 Buckets.
Here are some AWS S3 Bucket commands:
- aws s3 mb s3://bucket-name (To create new bucket)
- aws s3 mb s3://bucket-name/folder -name (To list inside the folder)
- aws s3 rb s3://bucket-name (To delete bucket)
- aws s3 rb s3://bucket-name --force (To delete stored all objects and bucket itself)
- aws s3 mv s3://bucket-name/example s3://my-bucket/ (To move all objects from target to destination)
- aws s3 mv filename.txt s3://bucket-name (To move local file to AWS S3 Bucket)
- aws s3 mv s3://bucket-name/filename.txt ./ (To move AWS S3 Bucket to working directory)
- aws s3 cp s3://bucket-name/example s3://my-bucket/ (To copy all objects from one Bucket to another)
Pralad is highly motivated IT professional with experience in system administration and design, deployments, migrations and operations. He has over eight years of experience in the industry. Over the period, he has gained significant amount of knowledge and experience in various industry leading technologies including but not limited to AWS, Microsoft Windows, Linux and VMware.
His expertise lies in the areas of cloud computing, unified communication, storage, backup, networking and security in mission critical environments. In addition to these, he has experience in stakeholder and project management as well.
Get connected with Pralad:



0 Comments